新闻
你的位置:亚博「中国」yabo官方网站-登录入口 > 新闻 > 亚博体育就使用 Scoring 函数来辩论这种关系性-亚博「中国」yabo官方网站-登录入口
亚博体育就使用 Scoring 函数来辩论这种关系性-亚博「中国」yabo官方网站-登录入口
发布日期:2025-04-09 08:09 点击次数:130
君可知,咱们每天在网上的见闻,有若干是出自 AI 之手?
除了「驻防看!这个男东谈主叫小帅」让东谈主头皮发麻,
信得过的问题是,咱们无法远离哪些内容是 AI 生成的。
养大了这些擅长一册矜重瞎掰八谈的 AI,东谈主类面对的困难也随之而来。
(LLM:东谈主与 AI 之间怎么连最基本的信任齐莫得了?)
子曰,解铃还须系铃东谈主。近日,谷歌 DeepMind 团队发表的一项缱绻登上了 Nature 期刊的封面:

缱绻东谈主员设备了一种名为 SynthID-Text 的水印决策,可应用于坐蓐级别的 LLM,追踪 AI 生成的文本内容,使其无所遁形。

论文地址:https://www.nature.com/articles/s41586-024-08025-4
一般来说,文本水印跟咱们平时看到的图片水印是不相同的。
图片不错摄取昭着的防盗水印,或者为了不影响内容不雅感而只是修改一些像素,东谈主眼发现不了。
但本文添加的水印思要隐神态似不太容易。

为了不影响 LLM 生成文本的质地,SynthID-Text 使用了一种新颖的采样算法(Tournament sampling)。
与现存方法比较,检测率更高,何况大约通过竖立来均衡文本色量与水印的可检测性。
怎么阐发注解文本色量不受影响?径直放到自家的 Gemini 和 Gemini Advanced 上实战。
缱绻东谈主员评估了及时交互的近 2000 万个反应,用户反馈畴昔。
SynthID-Text 的完毕只是修改了采样门径,不影响 LLM 的考试,同期在推理时的蔓延也不错忽略不计。
另外,为了合营 LLM 的履行使用场景,缱绻者还将水印与臆度采样集成在沿途,使之信得过应用于坐蓐系统。
大模子的指纹
底下跟小编沿途来看下 DeepMind 的水印有何特有之处。
识别 AI 生成的内容,当今有三种方法。
第一种方法是在 LLM 生成的时刻留个底,这在本钱和隐痛方面齐存在问题;
第二种方法是过后检测,商酌文本的统计特征或者考试 AI 分类器,开动本钱很高,且适度在我方的数据域内;
而第三种即是加水印了,不错在文本生成前(考试阶段,数据驱动水印)、生成经过中、和生成后(基于剪辑的水印)添加。
数据驱动水印需要使用特定短语触发,基于剪辑的水印一般是同义词替换或插入异常 Unicode 字符。这两种方法齐会在文本中留住昭着的伪影。
SynthID-Text 生成水印
本文的方王法是在生成经过中添加水印。
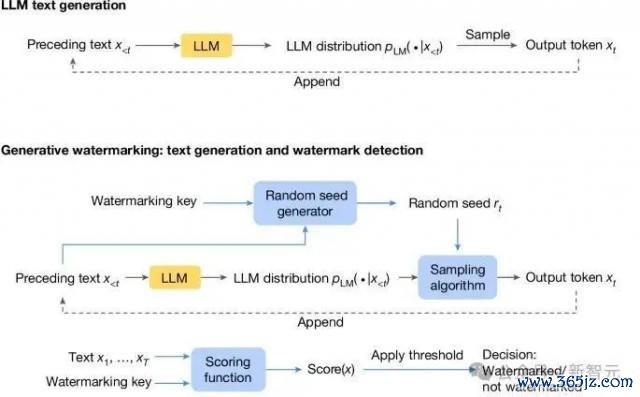
下图是范例的 LLM 生成经过:根据之前的 token 商酌刻下时刻 token 的概率分散,然后采样输出 next token。

在此基础之上,生成水印决策由三个新加入的组件构成(下图蓝色框):随即种子生成器、采样算法和评分函数。
随即种子生成器在每个生成要领(t)上提供随即种子 r ( t ) (基于之前的文本 token 以及水印 key),采样算法使用 r ( t ) 从 LLM 生成的分散中采样下一个 token。
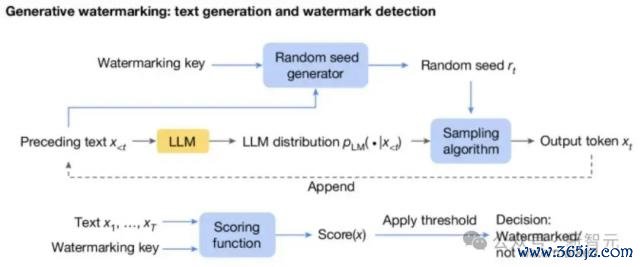
通过这种神志,采样算法把水印引入了 next token 中(即 r ( t ) 和 x ( t ) 的关系性),在检测水印的时刻,就使用 Scoring 函数来辩论这种关系性。
底下给出一个具体的例子:简便来说即是拿水印 key 和前几个 token(这里是 4 个),过一个哈希函数,生成了 m 个向量,向量中的每个值对应一个可选的 next token。

然后呢,通过打比赛的神志,从这些 token 中选出一个,也即是 SynthID-Text 使用的 Tournament 采样算法。
如下图所示,拿 2^m 个 token 参加 m 轮比赛(这里为 8 个 token3 轮比赛,token 可相通),
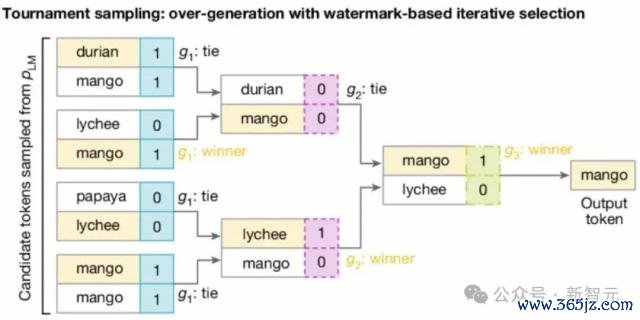
每轮中的 token 根据刻下轮次对应的向量两两 pk,胜者干涉下一轮,若是打平,则随即选一个胜者。
以下是算法的伪代码:

水印检测
根据上头的赛制,最终胜出的 token 更有可能在所有这个词的随即水印函数(g1,g2,...,gm)中取值更高,
是以不错使用底下的 Scoring 函数来检测文本:
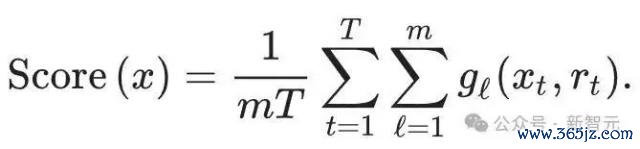
把所有这个词的 token 扔进所有这个词的水印函数中,终末商酌平均值,则带水印的文本常常应该得分高于无水印的文本。
由此可知,水印检测是一个进度的问题。影响评分函数检测性能的主要身分有两个。
领先是文本的长度:较长的文本包含更多的水印凭证,不错让检测有更多的统计细目性。
第二个身分是 LLM 自己的情况。若是 LLM 输出分散的熵十分低(意味着对交流的教导确凿老是复返透顶交流的反应),那么锦标赛采样(Tournament)无法选定在 g 函数下得分更高的 token。
此时,与其他生成水印的决策近似,关于熵较小的 LLM,水印的后果会较差。
LLM 自己的熵取决于以下几个身分:
模子(更大或更高档的模子常常更细目,因此熵更低);
来自东谈主类反馈的强化学习会减少熵(也称为形态崩溃);
LLM 的教导、温度和其他解码建立(比如 top-k 采样建立)。
一般来说,增多比赛的轮数(m),不错进步方法的检测性能,并缩短 Scoring 函数的方差。
可是,可检测性不会跟着层数的增多而无穷增多。比赛的每一层齐使用一些可用的熵来镶嵌水印,水印强度会跟着层数的加深而迟缓减轻。本文通过实验细目 m=30。
文本色量
作家为非失真给出了由弱到强的明确界说:
最弱的版块是单 token 非失真,默示水印采样算法生成的 token 的平中分散等于 LLM 原始输出的分散;
更强的版块将此界说彭胀到一个或多个文本序列,确保平均而言,水印决策生成特定文本或文本序列的概率与原始输出的分散交流。
当 Tournament 采样为每场比赛竖立正好两个参赛者时,即是单 token 非失果然。而若是应用相通的高下文掩码,则不错使一个或多个序列的决策不失真。
在本文的实验中,作家将 SynthID-Text 竖立为单序列非失真,这么不错保握文本色量并提供高超的可检测性,同期在一定进度上减少反应间的各类性。
商酌可彭胀性
生成水印决策的商酌本钱常常较低,因为文本生成经过仅波及对采样层的修改。
关于 Tournament 采样,在某些情况下,还不错使用矢量化来完毕更高效能,在实施中,SynthID-Text 引起的终点蔓延不错忽略不计。
在大畛域家具化系统中,文本生成经过常常比之前形色的简便轮回更复杂。
家具化系统常常使用 speculative sampling 来加快大模子的文本生成。
小编曾在将 Llama 考试成 Mamba 的著作中,先容过大模子的臆度解码经过。
简便来说即是用本来的大模子蒸馏出一个小模子,小模子跑得快,先生成出一个序列,大模子再对这个序列进行考证,由于 kv cache 的特点,发现不相宜条目的 token,不错精确回滚。
这么的作念法既保证了输出的质地,又充分期骗了显卡的商酌材干,诚然主要的处所是为了加快。
是以在实施中,生成水印的决策需要与臆度采样不绝合,才能信得过应用于坐蓐系统。
对此,缱绻东谈主员提议了两种带有臆度采样算法的生成水印。
一是高可检测性水印臆度采样,保留了水印的可检测性,但可能会缩短臆度采样的效能(从而增多全体蔓延)。
二是快速水印臆度采样,(当水印是单 token 非失真时)保留了臆度采样的效能,但可能会缩短水印的可检测性。
作家还提议了一个可学习的贝叶斯评分函数,以进步后一种方法的可检测性。当速率在坐蓐环境中很迫切时,快速带水印的臆度采样最灵验。
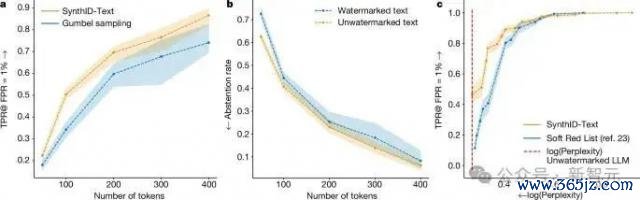
上图标明,在非失真类别中亚博体育,关于交流长度的文本,非失真 SynthID-Text 提供比 Gumbel 采样更好的可检测性。在较低熵的建立(如较低的温度)下,SynthID-Text 对 Gumbel 采样的校正更大。